Developpement de module : Etape 3
3° étape : Constituer et implanter le modèle de données pour le module
Normalisation du modèle
Une fois votre propre modèle de données constitué, nous allons le normaliser pour Moodle :
- Chaque table DOIT avoir une clef primaire nommée 'id', la librairie de manipulation des enregistrements utilise souvent ce présupposé.
- Les noms de colonnes sont écrits de préférence en minuscules, et non en "minuscules majusculées" (comme en Java, par exemple). Je fais pour ma part une seule entorse à ce régime, lorsque le champ est une clef étrangère sur un Id numérique ou je garde le suffixe Id majusculé : projectId ... mais c'est pas bien, pour les puristes.
- Les noms de colonne ne sont pas abrégés. On utilise de préférence des mots entiers, ou des suites de mots entiers.
- On préfère que les clefs étrangères soient placées en début de table, juste après la clef primaire, et avant les attributs qualifiants.
- Les booléens ne sont pas des ENUM('Y','N') ni ENUM('VRAI','FAUX') ni ENUM('true','false'). Les booléens sont codés en TINYINT à valeur 0 ou 1.
- Toutes les dates sont encodées en timestamp unix sous forme d'un INT(10).
- Toutes les descriptions sont des champs TEXT, qui recevront le contenu d'un éditeur WYSIWYG.
Règles moins impératives :
- Lorsqu'un champ TEXT est créé pour de la rédaction libre, on devrait créer immédiatement un champ de format de type entier pour mémoriser le format de rédaction pour ce texte. Moodle permet de rédiger en WYSIWYG, mais également dans des formats de balisage simplifiés proches du WiKi ou en HTML basique.
Jeu de tables d'un module
Le jeu de tables d'un module est en grande partie libre. Il existe cependant deux ou trois règles à suivre :
Il existe dans chaque module une table nommée :
{$CFG->prefix}{modulename}
(exemple, si le préfixe est le préfixe par défaut 'mdl_' : mdl_techproject). Cette table contient les paramètres mémorisés pour chaque instance (une instance est obtenue à chaque fois qu'on insère un module d'activité dans un cours).
Cette table contient trois catégories de champs :
- Les champs obligatoires :
- INT(10) id auto_increment UNSIGNED PRIMARY KEY : l'identifiant numérique d'instance
- INT(10) course UNSIGNED : la clef étrangère sur le cours où l'instance est implantée
- VARCHAR(255) name : le nom qui apparaît dans le "layout" du cours et dans le sommaire des activités de ce type.
- TEXT description : la description qui apparaît en face du nom dans le sommaire des activités de ce type.
- Les champs conseillés (ils apparaissent dans de nombreux modules et induisent des fonctionnements standard) :
- INT(10) {modulname}start
- INT(10) {modulename}end : Ces deux dates induisent une validité en temps limité du module.
- INT(10) timemodified : Cette date enregistre la date de dernière modification des paramètres d'instance.
- Les autres champs :
Ils stockent les paramètres et options propre à l'instance et dépendant de la sémantique du module. Pour la plupart, ils seront déterminés au fur et à mesure que vous construirez le module. Il s'agit de tout ce qui peut paramétrer le fonctionnement du module, activer ou désactiver certaines fonctionnalités, proposer des alternatives fonctionnelles à l'enseignant.
Nous reviendrons probablement sur ce modèle pour implanter quelques fonctionnalités standard telles que la notation de l'activité dans une prochaine discussion.
Les autres tables contiennent le jeu de données propre d'une instance particulière : Leur nom est formé ainsi : {$CFG->prefix}{modulename}_{tablesuffix},
ou {tablesuffix} est une séquence de mots minuscules séparés par des '_' : exemple mdl_techproject_assessment, ou mdl_techproject_task_status.
Leur clef primaire est la colonne
INT(10) id
comme introduit dans les règles générales.
Elles ont toutes* une clef étrangère
INT(10) {modulename}
(ou {modulename}id, pour ceux qui veulent expliciter les clefs étrangères) si vous comptez exploiter le mécanisme des groupes, ajouter une clef étrangère INT(10) group (ou INT(10) groupid pour les mêmes raisons que précédemment) permet d'isoler les valeurs de données groupe par groupe.
(*) On peut imaginer que quelques tables n'aient pas cette clef étrangère, lorsqu'on désire partager quelques informations entre toutes les instances. Mais ceci est rare et on préfèrera probablement un fichier de configuration local au module si ces paramètres sont d'ordre techniques.
Y a t-il des tables standardisées ?
Pas vraiment, mais il est toujours conseillé de regarder comment les développeurs précédents ont fait pour que le développement du module reste "dans l'esprit". Par exemple, si vous comptez noter l'activité avec un système d'évaluation élaboré, rassembler les notes dans une table {$CFG->prefix}{modulename}_assessment, n'est pas une mauvaise idée.
Où et comment implanter le modèle de données
En général, vous constituez le modèle de données dans votre implantation de développement. La technique habituelle est l'utilisation d'une application de gestion du modèle de données, comme phpMyAdmin pour la base de données MySQL.
Une fois la base prototype installée dans MySQL, on peut se servir de cette base pour générer le premier fichier install.xml qui permet l'installation d'un modèle compatible dans la plupart des bases supportées par Moodle.
Vous devez aller pour cela dans le menu

L'éditeur XMLDB est un outil puissant qui permet de gérer et générer correctement le fichier XML de méta-modèle de base de données (install.xml). Ecrire ce fichier à la main peut se révéler très difficile et très fastidieux.
Si votre module est à peu près implanté (son répertoire créé, un fichier version et le répertoire "db" créé à l'intérieur), vous pourrez retrouver son identité dans la liste des tous les fichiers d'initialisations gérés par XMLDB. Votre nouveau module doit y figurer en noir, sans lien, ce qui démontre que le fichier de méta-modèle n'est pas encore créé.
Voici un extrait de liste de modules (ici des blocs) démontrant trois situations identifiables :


Vous pouvez remarquer que l'entrée blocks/mnet_course_doors/db (1) permet déjà le chargement du fichier dans l'éditeur. Il s'agit d'un plugin conforme à l'implantation dans Moodle. Son fichier install.xml existe déjà.
L'entrée blocks/message/db (2) ne permet ni la création ni aucune autre manœuvre sur le fichier install.xml. C'est probablement que le répertoire "db" n'existe lui-même pas.
Enfin, l'entrée blocks/myCourses/db permet la création du fichier install.xml. C'est donc probablement que sa stratégie d'installation du modèle de données est une ancienne stratégie antérieure à la version 1.8.
Conduite de la procédure dans l'éditeur XMLDB
Nous allons entrer dans l'éditeur pour créer le fichier d'installation d'un module. Vous pourrez suivre ce processus pour votre nouveau module.
La première chose à faire est de créer le fichier en cliquant sur le lien "créer". Une fois créé, vous obtenez l'affichage suivant (nous allons procéder sur un module écrit par Jeff Graham, le module task).


Le fichier install.xml a été créé sur le disque dur de votre PC de développement. Il est totalement vide. Il faut le charger dans l'éditeur pour pouvoir le travailler. Une fois chargé vous obtenez l'affichage suivant :


Vous pouvez alors activer l'éditeur pour travailler le contenu du fichier. Cliquez sur "modifier" :
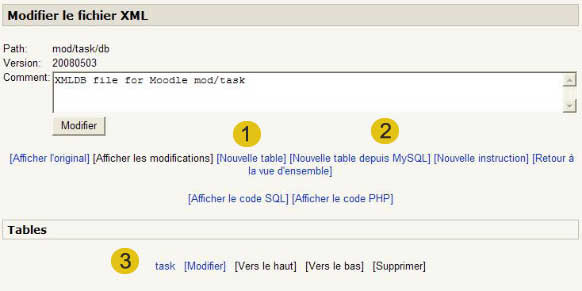

Vous obtenez un premier écran où vous pouvez créer les tables manuellement (1), ou les relire de votre prototype dans MySQL (2). Vous pouvez remarquer que la première table (3), celle qui correspond aux instances du plugin a été créée pour vous.
Si vous modifiez cette table pour voir comment elle est définie, vous avez la surprise de n'y trouver qu'un seul champ "id". C'est un défaut reconnu de l'éditeur XMLDB qu'il faut contourner :
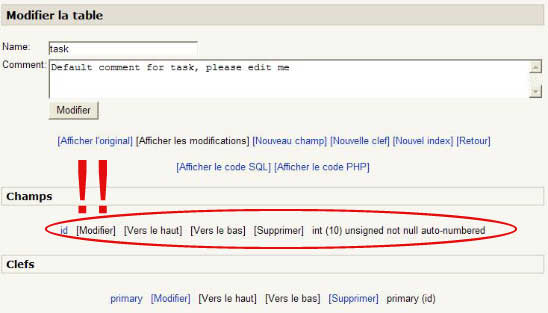

La suite de ce tutoriel vous indiquera une procédure pour effectuer ce contournement.
Vous allez maintenant ajouter une deuxième table à votre modèle. Sortez de l'écran précédent en cliquant sur "Retour" et cliquez sur le lien "Nouvelle table depuis MySQL". Nous avons ensuite choisi la première table commençant par le préfixe "task_" :
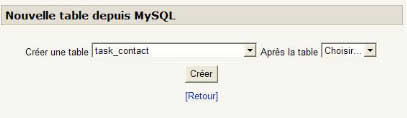

Cette table contient bien un certain nombre de champs que nous allons retrouver dès la table créée.
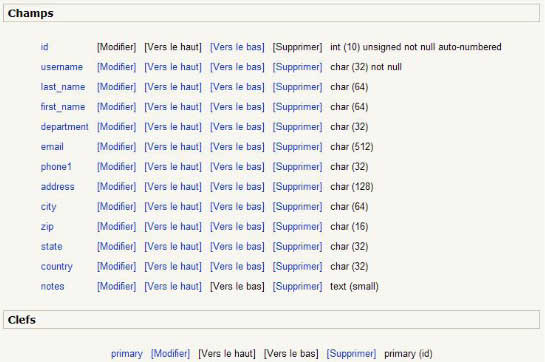

Il ne vous reste plus qu'à recommencer la même opération pour toutes les tables préfixées du nom du plugin, sans oublier de sauvegarder à la fin le fichier :


Contourner le bug de l'éditeur XMLDB
Au premier chargement du fichier install.xml, seul le champ "id" est créé dans la première table pré-configurée. Le contournement de ce défaut consiste, après avoir créé la DEUXIEME table, à :
- détruire la première table (vous ne pouvez pas le faire AVANT d'en avoir une deuxième).
- réimporter la première table.
- remonter cette première table "vers le haut" pour rétablir l'ordre correct.
Vous pouvez alors générer les suivantes.