Moodle 2.0
Introduction
This page describes the calculations of these quiz and question statistics. You can find a succinct description of their meanings here Quiz report statistics. Also see the documentation for the Quiz statistics report itself.
General issues
Quizzes that allow multiple attempts
For quizzes that allow multiple attempts, by default the report should only include data from the first attempt by each student. (The data for subsequent attempts probably does not satisfy the assumptions that underlie item analysis statistics.) However, there should be an option 'Include data from all attempts', which should have a disclaimer that this may be statistically invalid either near it on screen, or possibly in the help file. (For small data sets, it may be better to include all data.)
Using the first attempt also avoids problems caused by each attempt builds on last.
Within the analysis, when multiple attempts per student are included, each attempt is treated as an independent attempt. (That is, we pretend each attempt was by a different student.)
Adaptive mode
Adaptive mode does not pose a problem. Item Analysis just supposes that each item in the test returns a score, and these scores are added up to get the test score. Therefore Item Analysis does not care about adaptive/non-adaptive mode. However, just to be clear, for an adaptive question, the score used in the calculation is the final score for the item, including penalties.
Certainty based marking
Similarly, should CBM, and/or negative scoring for multiple choice questions be implemented, we just use the final item score in the calculations, making sure that the formulae are not assuming that the minimum item score is zero.
Incomplete attempts
There is an issue about what you do when not all students have answered all questions. Depending on how you handle these missing items, you distort the statistics in different ways.
There are basically two reasons why a student may not have answered a particular question:
- they may have chosen to omit it, or
- they may have run out of time, if the test is timed. In this case, omitted questions tend to be towards the end of the test.
Available approaches for handling this are:
- treat omitted items as having a score of 0.
- exclude any attempt with missing scores from the analysis.
- Analyse each question separately - and when analysing a particular question, just include students who answered that question in the analysis.
I think we should implement 1 for now. This is how Moodle currently works - a blank answer is marked and receives a score of zero, and so is indistinguishable from a wrong answer. Item analysis is most important for summative tests, and the result of that question being in the test is that it gave that student a contribution of 0 marks towards their final score.
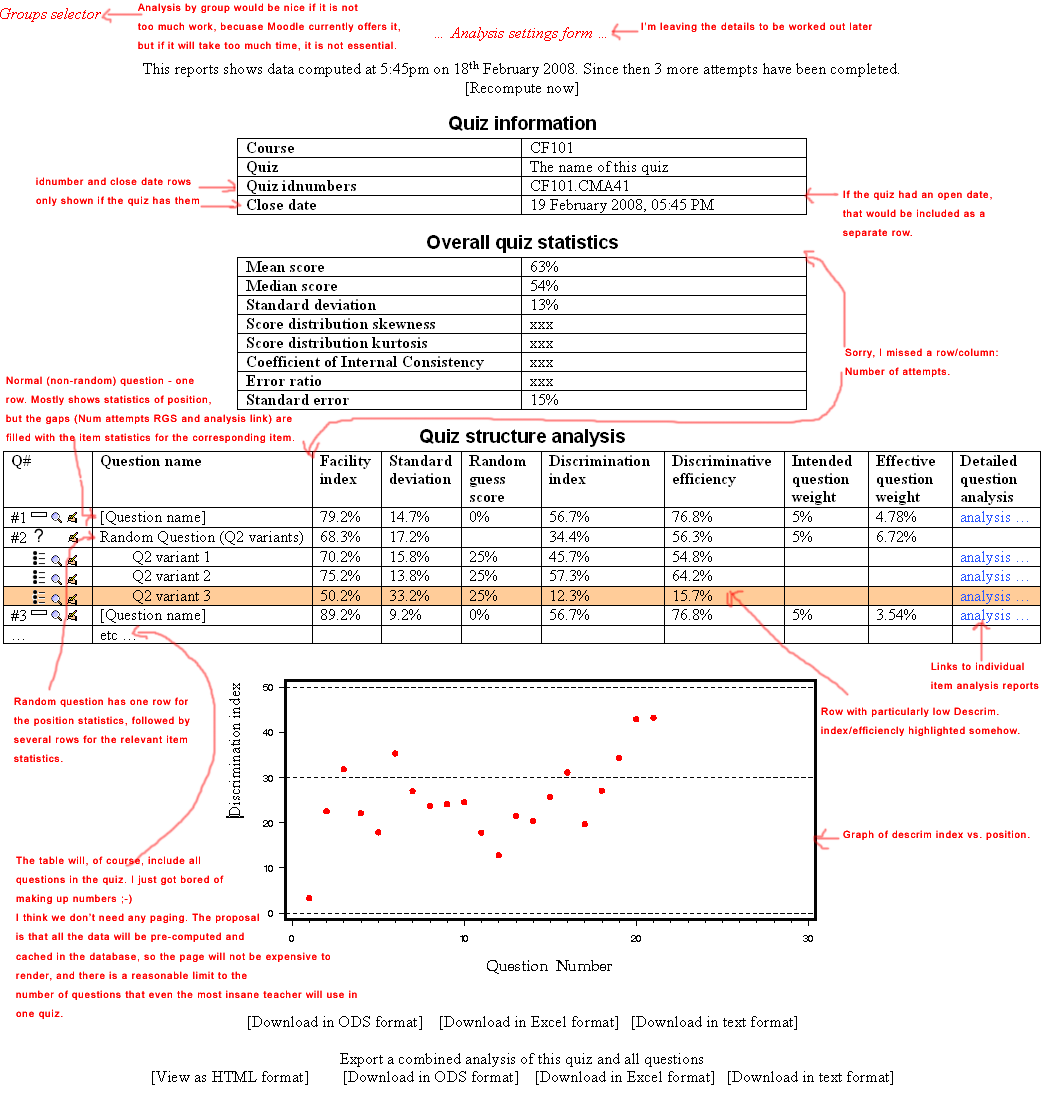
Random questions
In a quiz with random questions not all students will have attempted the same set of questions. To account for this, the analysis below distinguishes between positions in the test, and test items.
Notation used in the calculations
We have a lot of students , who have completed at least one attempt on the quiz.

The test has a number of positions .

The test is assembled from a number of items .

Because of random questions, different students may have recieved different items in different positions, so is the item student received in position .



Let be the set of items that student saw. Let be the set of students who attempted item .



Each position has a maximum and minimum possible contribution to the test score, and . At the moment in Moodle, is always zero, but we cannot assume that will continue to be the case. is database column quiz_question_instances.grade.


Then, each student achieved an actual score on the item in position . So .


should be measured on the same scale as the final score for the quiz. That is, scaled by quiz_question_instances.grade, but that is already how grades are stored in mdl_question_states.
We can also think of the student's score on a particular item . However, in this case, the score should be measured out of the Default question grade for this question. Also, there is a ( = Default question grade) and (currently, zero, but if we allow negative marking, that will change).



.

Each student has a total score

Similarly, there are the maximum and minimum possible test scores

and

Intermediate calculations
To simplify the form of the formulas below, we need some intermediate calculated quantities, derived from the ones above.
Student's rest of test score for a position: .

For any quantity that depends on position (for example or ), it's average is denoted with an overbar, and is an average over all students, so


.

When a quantity is a property of an item, a bar denotes an average over all students who attempted that item, so
.

Similarly we have the variance of a quantity depending on position:

and for a quantity depending on items:
.

Finally, we need co-variances of two quantites, for example:

.

Position statistics
Facility index
This is the average score on the item, expressed as a percentage:
.

The higher the facility index, the easier the question is (for this cohort of students).
Standard deviation
Again expressed on a percentage scale:
.

Discrimination index
This is the product moment correlation coefficient between and , expressed on a percentage scale. That is,
.

The idea is that for a good question (or at least a question that fits in with the other questions in the test), students who have scored highly on the other parts of the test should also have scored highly on this question, so the score for the question and the score for the test as a whole should be well correlated.
The weakness of this statistic is that, unless the facility index is 50%, it is impossible for the discrimination index to be 100%, or, to put it another way, if is close to 0% or 100%, will always be very small. That makes interpreting this statistic difficult.


Discriminative efficiency
This gets around that weakness in the discrimination index by expressing as a percentage of the maximum value it could have taken given the scores the students got on this question, and the test as a whole. That is:


where is defined as follows:

When you compute , you do the sum
which involves a term for each student combining their question score and rest of test score. That is, you start with an array of with an array of corresponding , one for each . To compute , you just sort these two arrays before applying the above formula. That is, for the purpose of computing , you pretend that the first student scored the lowest and the lowest , the second student scored the second lowest and the second lowest , and so on to the last student, who scored the highest and .


Intended question weight
How much this question was supposed to contribute to determining the overall test score.
.

Effective question weight
This is an estimate of what proportion of the variance in the students' test scores is due this question.
.

Item statistics
Number of attempts
The number of students who got this question as part of a quiz attempt. This is just .
Random guess score
This is the score that the student would have got by guessing randomly. It depends on the question type. For types like shortanswer, it is 0 - or the score associated with answer '*', if there is one.
For multiple choice questions (including matching, truefalse, etc.) it is the average score over all the possible choices.
(There should probably be a method in the question type class to compute this.)
Facility index
.

Standard deviation
.

Discrimination index
.

(It is not possible to define because it is conceivable that the same item may have been chosen in different positions with different weights, so we substitute instead.)


Discriminative efficiency
.

Test statistics
Number of Attempts
This is .

Note that depending on the options, we may be counting one or all attempts per student.
Mean Score
Test mean

Median Score
Sort all the , and take the middle one if S is odd, or the average of the two middle ones if S is even.

Standard Deviation
Test standard deviation .

Skewness and Kurtosis
Probably of limited interest, but included for completeness. Skewness is a measure of the asymmetry in a distribution. Kurtosis - imagine a normal distribution. Kurtosis tells you if your distribution has more of a bulge, but thinner tails, or vice-versa.
First calculate:



Then compute



Then
Skewness

Kurtosis

Coefficient of Internal Consistency
This is on a percentage scale

Also called Cronbach's alpha in the literature.
Error Ratio
Also a percentage.

Standard Error

{kind=link}
{kind=link}
{kind=link}
These last three are to do with estimating how reliable the test scores are. If you take the view that the score the student got on the test on the day is a combination of their actual ability and a random error (how lucky they were on the day of the test), the the standard error is an estimate of the luck factor. So if SE ~= 10, and the student scored 60, then you can be quite confident that their actual ability is between 50 and 70.